Inception Of Things
Part 2: K3s and three simple applications
L'objectif de cette partie est de déployer 3 versions d'une même application dans un cluster k3s, et de les exposer via un Ingress qui route le trafic selon le nom de domaine utilisé.
.env.example
Comme pour la partie 1, les variables sont centralisées dans un .env , cette fois avec une seule VM :
SERVER_IP=192.168.56.110
SERVER_VM_NAME=wilS
HCP_CLIENT_ID=f2a1ac1961dc3c743d01b83e634e1c5f
HCP_CLIENT_SECRET=114bda22fce128df4195a6425d38e873f27acff8c60fff74db45c797a1bb36b7
BOX=IOTTitans/alpine-3.23.2
BOX_VERSION=1.0.0
Commandes curl pour tester les différentes applications et nodes respectifs:
Une fois le cluster déployé, vous pouvez vérifier que chaque application répond correctement. L'astuce : on passe le nom de domaine via l'en-tête HTTP Host, ce qui simule ce que ferait un vrai navigateur.
# expected output: <td>app1-deployment-[node id]-[pod id]</td>
curl -s -H "Host: app1.com" http://192.168.56.110 | grep app
# expected output: <td>app2-deployment-[node id]-[pod id]</td>
# the pod id should alternate between the 3 pods
curl -s -H "Host: app2.com" http://192.168.56.110 | grep app
# expected output: <td>app3-deployment-[node id]-[pod id]</td>
curl -s -H "Host: app3.com" http://192.168.56.110 | grep app
# expected output: <td>app3-deployment-[node id]-[pod id]</td>
# app3 is setup as the default deployment served
curl -s http://192.168.56.110 | grep app
Les objets Kubernetes utilisés
Voici les trois types d'objets que vous allez manipuler, et comment ils s'articulent :
Requête HTTP entrante
↓
[ Ingress ] ← route selon le Host header
↓
[ Service ] ← adresse stable vers les pods
↓
[ Deployment ] ← gère les pods et leur état
↓
[ Pod(s) ] ← container(s) qui font tourner l'app
Voici comment les différents objets interagissent ensemble au sein du cluster :
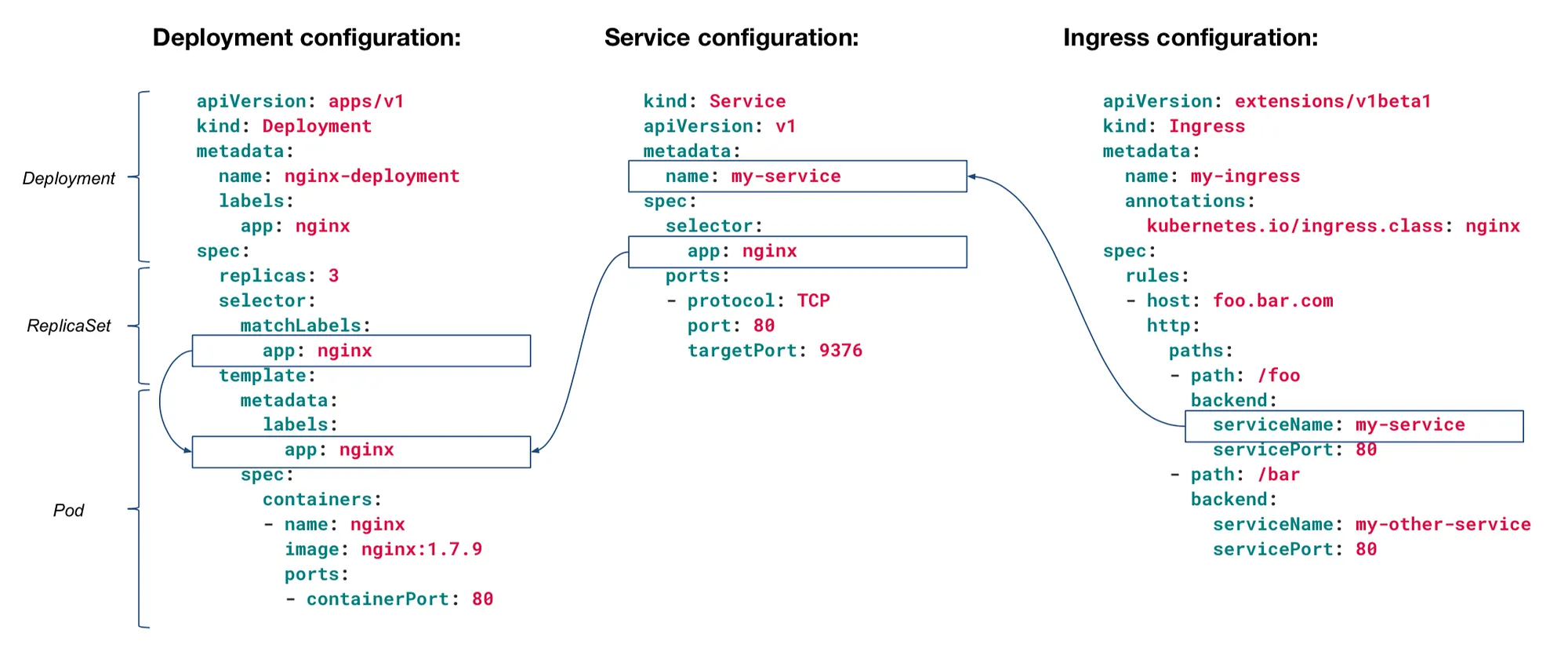
Tous les objets Kubernetes sont décrits par un fichier YAML qui contient toujours 4 champs racine : apiVersion, kind, metadata, spec.
Deployment
Un Deployment déclare l'état souhaité de vos pods : quelle image utiliser, combien de replicas, sur quel port écouter… Le cluster s'assure ensuite en permanence que cet état est respecté.
apiVersion: apps/v1
kind: Deployment
metadata:
name: app1-deployment
spec:
strategy:
type : Recreate
selector:
matchLabels:
app: app1
replicas: 1
template:
metadata:
labels:
app: app1
spec:
containers:
- name: app1
image: paulbouwer/hello-kubernetes:1
ports:
- containerPort: 80
env:
- name: MESSAGE
value : "Hello from app1"
- name: PORT
value: "80"
Le yaml de l’objet Deployment se divise en 4 parties :
- kind : précise le type d’objet décrit par le fichier yaml
- metadata :
Ici les metadata ne contiennent qu’une seule paire clé-valeur : le name. Ce name permet d’identifier l’objet et sert de base de nommage pour les ressources créées par le deployment. Ainsi les pods issus de ce déploiement auront un nom de type “app1-deployment-5465fc44cc-6n5gq" . Les metadata peuvent également avoir d’autres clé-valeur comme le namespace, un label ou encore des annotations.
- spec
Dans spec on distingue deux sous-parties : la première est le ReplicaSet et la seconde est template des pods à créer. Le déploiement crée un ReplicaSet et ce ReplicaSet crée les pods à partir du template qui suit. Au sein du ReplicaSet, on trouve un Selector. Son rôle est de permettre au déploiement de reconnaître les pods dont il a la charge. Ici ce sont les pods ayant pour label app1. Il existe d’autres méthodes que matchLabel pour permettre au déploiement comme par exemple matchExpression.
Concernant les specs du (ou des) pods, ils possèdent une liste de containers. Dans notre cas le pods contient un seul container qui écoute sur le port 80. Pour information les containers sont exécutés par un runtime appelé containerd. Cette partie spec est assez similaire à un docker compose.
Lorsqu’on apply un objet il est stocké dans la base de données etcd. Voici ce qui se passe au sein du cluster lorsque l’on utilise la commande kubectl apply -f service.yaml
kubectlenvoie une requête HTTP REST à l’API Server- l’API Server valide le YAML
- il enregistre l’objet Service dans la base etcd
- les composants du cluster observent cet objet et réagissent
Service
Un Service sert à fournir une adresse stable (IP/DNS) et un load-balancing vers un ensemble de Pods. Les pods ont des IP qui changent d’un redémarrage à l’autre. Le Service assure un accès constant aux pods sur une IP stable. C’est une règle réseau déclarative.
apiVersion: v1
kind: Service
metadata:
name: app1-service
spec:
selector:
app: app1
ports:
- protocol: TCP
port: 80
targetPort: 80
On retrouve les 4 mêmes parties que pour l’objet déploiement : apiVersion, kind, metadata et spec.
Concernant metadata, il possède une paire clé-valeur name = app1-service. app1-service est le nom DNS de ce service au sein du cluster.
spec explique comment ce service doit fonctionner :
- selector : permet de renvoyer le trafic vers un pod qui est sélectionné par son label. En l’occurrence ce sont tous les pods ayant pour label app1.
- ports : ce bloc décrit que quel port le service écoute (port) et vers quel pod il renvoie le trafic (targetPort)
Pour résumer ce fichier signifie :
Crée un objet Kubernetes de type Service, nommé app1-service. Ce Service doit cibler tous les Pods qui portent le label app=app1. Il expose un port 80 en TCP, et tout trafic reçu sur ce port doit être redirigé vers le port 80 des Pods sélectionnés.
Ingress
L’ingress sert à exposer les services vers l’extérieur. Autrement dit, il sert à gérer l’accès HTTP/HTTPS entrant vers des Services du cluster. C’est un routeur, il redirige une url vers un service ou vers un autre.
kind: Ingress
metadata:
name: ingress-part-two
spec:
rules:
- host: app_name1.com
http:
paths:
- path: "/"
pathType: Prefix
backend:
service:
name: app_name1-svc
port:
number: 80
- host: app_name2.com
http:
paths:
- path: "/"
pathType: Prefix
backend:
service:
name: app_name2-svc
port:
number: 80
- http:
paths:
- path: "/"
pathType: Prefix
backend:
service:
name: app_name3-svc
port:
number: 80
Bon on commence à avoir l’habitude… tous les objets kubernetes sont décrits par un yaml qui possède à la racine apiVersion, kind, metadata et spec.
metadataest là pour donner un name à notre objet. Quant àspec, il est là pour décrire le comportement attendu par notre ingress.rulesest un nouveau ???? que nous n’avons pas encore rencontré. Il s’agit de la liste des règles de routage vers les différents services. Il redirige le trafic extérieur. Dans la première règle nous avons :host: app1.comqui signifie que si l’en-tête de la requête est app1.com le trafic devra être redirigé vers le service app1-service.http: signifie que l’ingress ne répondra qu’aux requêtes httppathsest la liste des chemins à router. Dans notre cas, il n’y a qu’un seul chemin :/ce qui signifie tous les chemins. Remarque : le test suivant :curl http://192.168.56.110/prout/proutrenvoie une erreur. Mais ce n’est pas la faute de l’ingress qui aurait mal redirigé. Il s’agit de la réponse de notre app qui n’est pas en mesure de traiter cette requête.port.number: il s’agit du port sur lequel l’application écoute.
Il y’a 2 notions à distinguer au sujet de l’objet Ingress:
- l’objet
API Kubernetes Ingressqui est uneAPIqui permet de définir des règles de routing et de gérer l’accès d’utilisateurs extérieurs au cluster Kubernetes aux services déployés dans ce cluster. - l’
Ingress Controllerest l’implémentation de l’API, il va prendre la configuration définie (Ingress Resource Information) et l’applique. Il run dans un pod du cluster Kubernetes. Il existe plusieurs solutions faisant office d’Ingress Controller: nginx, traefik, haproxy …k3sinstalleTraefikcommeIngress Controllerpar défaut.
La configuration de routing est faite dans le yaml en tant que Ingress Resource. Cette configuration est ensuite utilisée par l’Ingress Controller qui va appliquer les règles de routing récupérées des Ingress Resources. L’ingress Controller fait office de load balancer.
La doc de Kubernetes recommande d’utiliser Gateway au lieu d’Ingress, l’API Ingress n’est plus développée mais reste disponible à l’utilisation.
📚 Sources https://www.youtube.com/watch?v=NPFbYpb0I7w
https://www.ibm.com/think/topics/kubernetes-ingress
https://docs.k3s.io/networking/networking-services
https://kubernetes.io/docs/concepts/services-networking/ingress/
https://devopscube.com/kubernetes-ingress-tutorial/
https://blog.stephane-robert.info/docs/conteneurs/orchestrateurs/kubernetes/ingress/