ft_linear_regression
Théorie
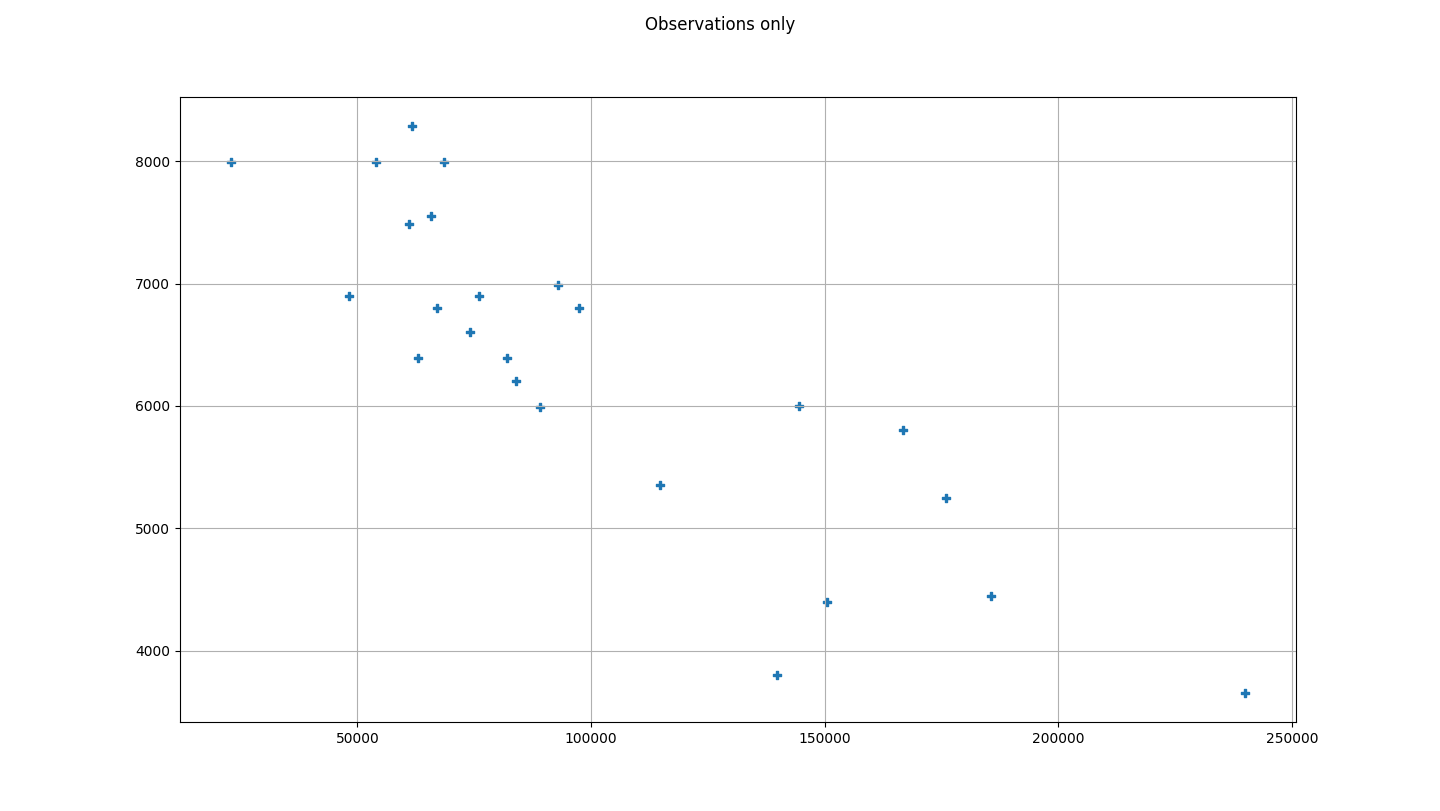
Le dataset
Le sujet fournit le dataset suivant :
| km | price |
|---|---|
| 240000 | 3650 |
| 139800 | 3800 |
| 150500 | 4400 |
| 185530 | 4450 |
| 176000 | 5250 |
| 114800 | 5350 |
| 166800 | 5800 |
| 89000 | 5990 |
| 144500 | 5999 |
| 84000 | 6200 |
| 82029 | 6390 |
| 63060 | 6390 |
| 74000 | 6600 |
| 97500 | 6800 |
| 67000 | 6800 |
| 76025 | 6900 |
| 48235 | 6900 |
| 93000 | 6990 |
| 60949 | 7490 |
| 65674 | 7555 |
| 54000 | 7990 |
| 68500 | 7990 |
| 22899 | 7990 |
| 61789 | 8290 |
Voici la représentation graphique de ce dataset :
Le modèle
En second lieu, le sujet impose d’optimiser le modèle suivant :
Le but de l’exercice est donc de déterminer pour quelles valeurs de theta0 et theta1 notre modèle est le plus efficace pour prédire le prix d’une voiture selon son kilométrage. Ces 2 paramètres doivent être optimisés en utilisant l’algorithme de la descente de gradient optimisé. On peut déjà estimé à l’œil sur le graphique que :
Pour déterminer si le modèle est efficace dans ces prédictions, nous comparons ses prédictions aux valeurs fournies par le dataset. Cette comparaison est permise grâce à la fonction de coût.
La fonction de coût
Elle n’est pas donné par le sujet mais après quelques recherches sur internet, la voici :
Ou encore…
Cette fonction ressemble au calcul de la variance. Le résultat est la moyenne du carré des erreurs entre les valeurs prédites par le modèle et les valeurs observées. Ainsi plus la valeur de cost est faible, plus le modèle est performant pour faire des prédictions.
Il est possible d’en faire une représentation graphique en mettant les valeurs de theta0 en abscisse et les valeurs de theta1 en ordonnée. Le résultat du calcul de la fonction sera sur l’axe z. On obtient le résultat suivant :
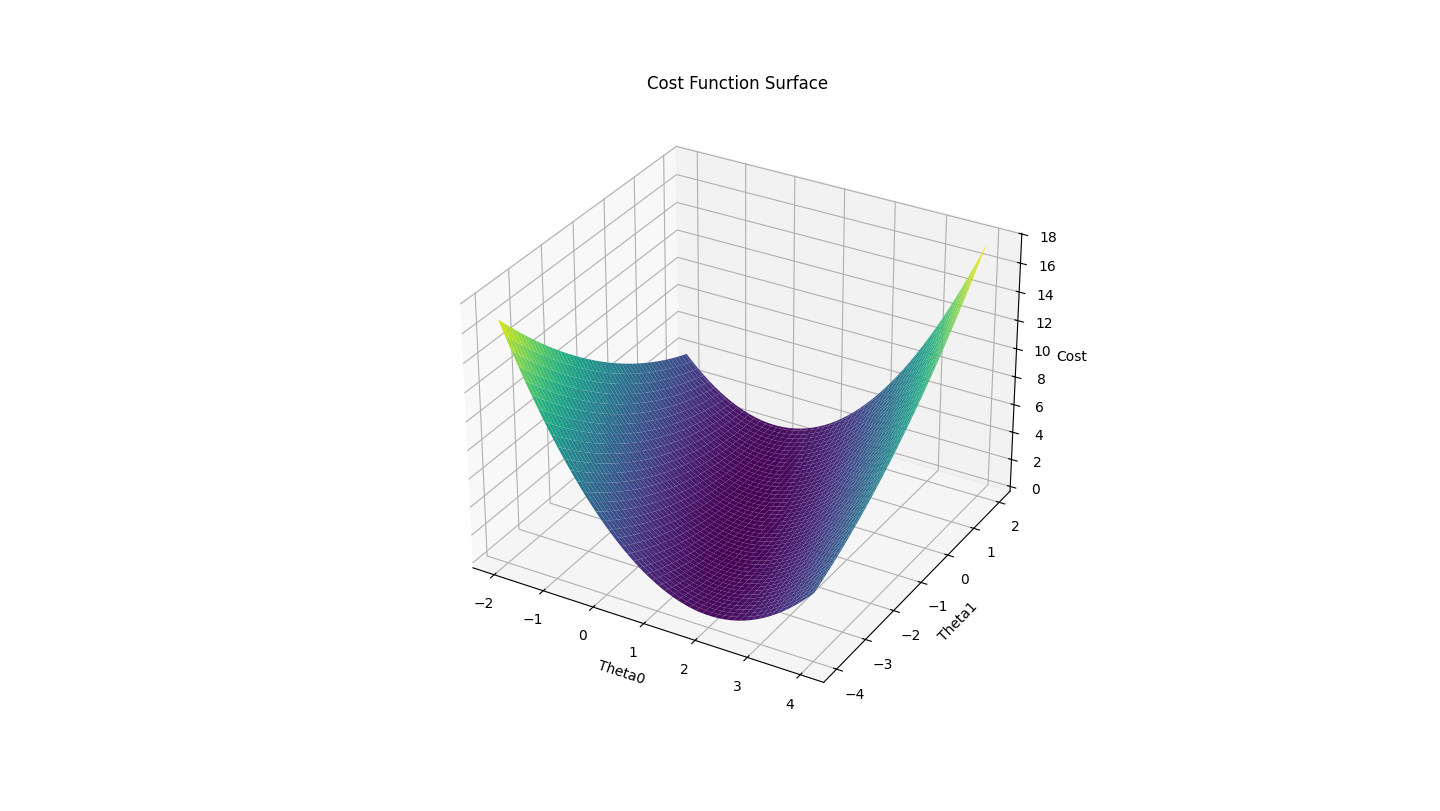
N.B. : les valeurs des paramètres sur le graphiques ne correspondent pas à la réalité car elles ont été normalisées. Nous verrons pourquoi plus loin.
Le but de l’exercice est donc de trouver pour quelles valeurs de theta0 et theta1 cette fonction atteint son minimum.
Dérivées partielles de la fonction de coût
Le sujet impose de débuter l’entraînement de notre modèle en initialisant theta0 = 0 et theta1 = 0. Nous pouvons d’ores et déjà calculer la valeur de notre fonction de coût pour ce cas là. On obtient : cost(0,0) = 41761038.5 ou encore cost(0,0) = 41761038.58 sur les valeurs normalisées du dataset. Comme nous pouvons le constater la fonction de coût a une valeur très élevée dans ce cas.
La question qui se pose maintenant est : comment choisir d’autres valeurs pour theta0 et theta1 pour que notre fonction de coût présente un meilleur résultat ?
La réponse est simple : nous allons utiliser les dérivés de cette fonction de coût ! De façon très basique la dérivé est une quantité qui nous fournit 2 informations très utiles sur une fonction :
- Elle nous indique si cette fonction est croissante ou décroissante. Si la dérivée est positive la fonction est croissante. Si la dérivée est négative la fonction est décroissante.
- Elle nous indique également si la fonction croit (ou décroit) rapidement. Plus la valeur de la dérivée est élevée plus la fonction croit (ou décroit) rapidement.
Pour plus de détail, je conseille de regarder la suite de vidéo de Lé Nguyen Hoang sur le sujet (cf. sources).
Comme nous avons 2 paramètres à optimiser, nous avons besoin de 2 dérivées : la dérivée partielle de cost selon theta0 et la dérivée partielle de cost selon theta1. Qu’à cela ne tienne nous allons les calculer immédiatement !
Commençons par développer l’équation de notre fonction de coût :
Nous obtenons :
Dérivée partielle selon theta0
Nous pouvons calculer la dérivée de notre fonction de coût terme à terme selon theta0, nous obtenons :
Or, le sujet nous impose de mettre à jour nos paramètres a l’aide de la formule suivante :
Nous pouvons constater que cela est cohérent car nous retrouvons la formule de notre dérivée précédemment calculée.
Dérivée partielle selon theta1
De même nous pouvons calculer la dérivée terme à terme de notre fonction de coût selon theta1 :
De la même manière, nous retrouvons la formule de notre dérivée dans la formule imposée par le sujet pour mettre à jour theta1.
Nous pouvons cependant remarquer que le facteur 2 des dérivées que nous avons calculer à été remplacé par le learningRate dans la formule fournis par le sujet. Il est temps de se pencher sur ce paramètre…
Le taux d’apprentissage
Grâce au calcul de nos dérivés nous savons si nous devons augmenter ou diminuer la valeur de theta0 et de theta1 à chaque itération. Parfait ! Mais de combien ? C’est là que le taux d’apprentissage entre en jeu ! Le taux d’apprentissage est le pourcentage de la dérivée que nous soustrairont à theta0 et theta1 afin de les mettre à jour à chaque itération.
Nouvelle question : quelle valeur donner à ce learningRate ?
Ici nous sommes face à un dilemme :
- soit nous choisissons un learningRate élevé : dans ce cas notre algorithme va converger après un faible nombre d’itération, cependant le revers de la médaille est que nous risquons de passer à côté du minimum de notre fonction de coût. Dit autrement si nous faisons de trop grands pas, nous risquons d’enjamber le minimum de la fonction sans nous en rendre compte.
- soit nous choisissons un learningRate faible : dans ce cas nous allons faire de tous petits pas qui nous permettrons plus certainement de tomber sur le minimum de notre fonction mais au prix d’un très grand nombre de calcul
Alors comment fait-on ? Eh bien, je n’ai pas de recette miracle à part celle de tester notre algo avec différents taux d’apprentissage et de voir quel learningRate permet une convergence satisfaisante en un temps raisonnable.
Normalisation du dataset
Avant de lancer notre algorithme à la recherche du minimum de notre fonction de coût, nous allons lui simplifier la tâche grâce à la normalisation des données.
Qu’est ce que normaliser les données ?
Comme nous l’avons dit, les 2 paramètres à optimiser sont theta0 et theta1. Theta0 doit avoir une valeur optimale entre 8000 et 9000. Quand à theta1, il semblerait que sa valeur optimale soit comprise entre -0,1 et -0,3. Nous pouvons constater que l’ordre de grandeur de nos 2 paramètres est différent (il y a un facteur de x10000) entre les 2.
Normaliser les données permets de régler ce problème. Dans notre cas j’ai utilisé (arbitrairement) une normalisation min-max.
En normalisant ainsi les données, on obtient le dataset suivant :
| km normalisés | price normalisés |
|---|---|
| 1 | 0 |
| 0.538463664 | 0.032327586 |
| 0.587749481 | 0.161637931 |
| 0.749102952 | 0.172413793 |
| 0.705206333 | 0.344827586 |
| 0.423309888 | 0.36637931 |
| 0.662829743 | 0.463362069 |
| 0.304471191 | 0.504310345 |
| 0.560112574 | 0.50625 |
| 0.281440436 | 0.549568966 |
| 0.272361712 | 0.590517241 |
| 0.184987632 | 0.590517241 |
| 0.235378925 | 0.635775862 |
| 0.343623475 | 0.67887931 |
| 0.203135868 | 0.67887931 |
| 0.244706381 | 0.700431034 |
| 0.116701443 | 0.700431034 |
| 0.322895795 | 0.719827586 |
| 0.175264048 | 0.827586207 |
| 0.197028111 | 0.841594828 |
| 0.143255904 | 0.935344828 |
| 0.210045094 | 0.935344828 |
| 0 | 0.935344828 |
| 0.179133214 | 1 |
Pourquoi normaliser les données ?
Cela est nécessaire car les valeurs des dérivées partielles de theta0 et theta1 sont très différentes. Par à la première itération, on obtiendrait :
- drv_theta0 (0,0) = -6331.833333333333
- drv_theta1 (0,0) = -582902525.4166666
Comme nous pouvons le constater il y a un facteur 100000 entre la valeur de la dérivée pour theta0 et la valeur de la dérivée pour theta1. Or le learningRate pour la mise à jour de theta0 et theta1 est le même pour nos deux paramètres. Par conséquent, l’algorithme ne fonctionne pas. Les 2 paramètres sont mis à jour à des “vitesses” différentes. On pourrait régler ce problème en utilisant un learningRate différent pour chaque paramètre mais ce serait un bricolage peu fiable.